I fjol höll vi ett ”hack” om kulturarvsdata i Riksantikvarieämbetets lokaler i Visby, där deltagare från flera olika institutioner var med för att hitta gemensamt värde genom att länka ihop sina respektive datamängder. Hacket var så lyckat, att vi ordnade en uppföljare förra veckan, i anslutning till Vårmötet i Umeå och i samarbete med HUMlab på Umeå universitet.
Den här gången på ”ArkHack 2.0” lockade vi flera deltagare från ett antal olika organisationer. Hacket hölls som ett kollaborativt labb över två dagar 7:e-8:e april på Umeå universitets häftiga HUMlab-X lokaler, med målen att deltagarna skulle hitta kopplingar mellan sina respektive datamängder samt nya sätt att visa upp information från flera källor, lära känna olika verksamheters behov och informationsmängder, lära sig mer om teknik, metoder och attityder kring öppna länkade data, skapa bra förutsättningar för samverkan framöver… och framförallt att ha roligt! :) Det här var inte någon tävling, utan snarare ett sätt för deltagarna att lära sig mer om varandras information, och framförallt hitta kopplingar de emellan, med hjälp av öppna länkade data teknik.

(Foto: Henrik Löwenhamn)
På måndagen började vi med att spåna idéer och förslag på aktiviteter. Sedan, när deltagarna hade själv bestämt vad de ville jobba med, delade vi upp i sex grupper som skulle jobba på sex olika spår. Det var inte bara utvecklare som var med på hacket, utan även verksamhetsmänniskor som skulle bolla idéer om användarbehov, användningsfall, presentationssätt, osv. Dessa sex grupperna jobbade då tillsammans på måndagen och tisdagen, och höll regelbundna avstämningar mellan grupperna med vernissage för att främja kunskapsutbyte. På onsdag eftermiddag presenterades resultaten från hacket på ett seminarium inom programmet för Vårmötet.

(Foto: Henrik Löwenhamn)
Gruppernas medlemmar och deras arbete var som följande:
Martin Malmsten & Per Nilsson (Kb) – Ortnamn ur tidningsartiklar
Martin och Per jobbade med digitaliserade tidningsartiklar ur Kbs projekt DigiDaily, framförallt den fria delen från 1800-talet som där texterna inte är upphovsrättsskyddade. Målet var att extrahera ortnamn från artiklarna och helt länka de mot ett gemensamt ortnamnsregister (så att varje ortnamn skulle får en unik id, och för att underlätta vidarekopplingar till andra datamängder). Detta skulle möjliggöra ett antal olika intressanta forskningsfrågeställningar som annars inte skulle gå att svara på – t.ex. hur skrev storstadstidningar om landsbydgden? Och tvärtom? Vad säger detta om attityder om olika befolkningsgrupper? osv.
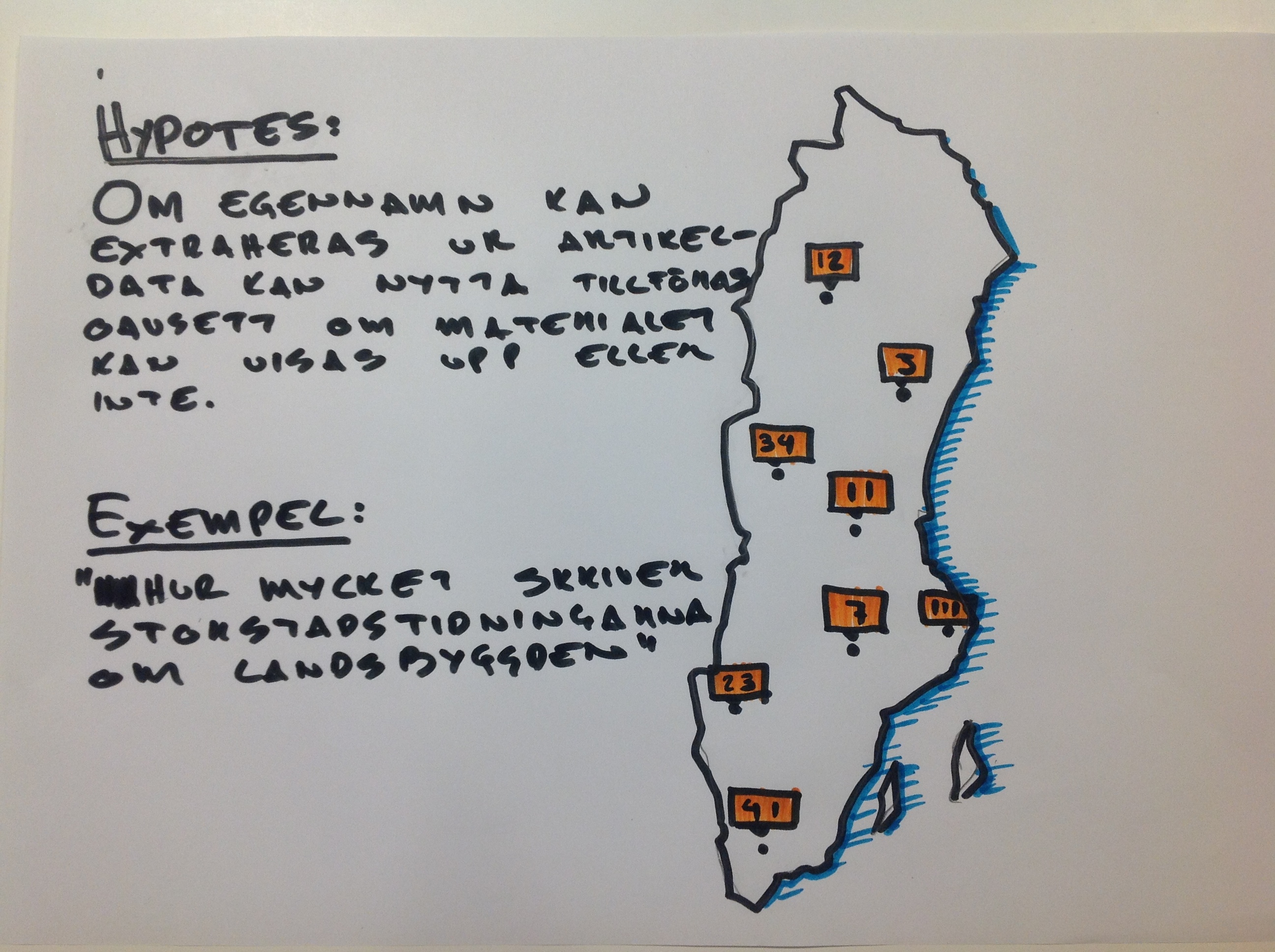
Gruppen lyckades hitta och extrahera ortnamnen, men stötte sedan på ett problem: ortnamn förekommer i tidningarna i ett antal olika sammanhang, inte alltid i löptexten till en artikel utan även i kontaktadresser, reklam, osv. Och sammanhanget har innebörd: att en av tidningarna hade t.ex. en färjetidtabell i flera decennier förvrängde datat något!
Stephanie Roth & Olof Olsson (SND) – Kopplingar SND/K-samsök
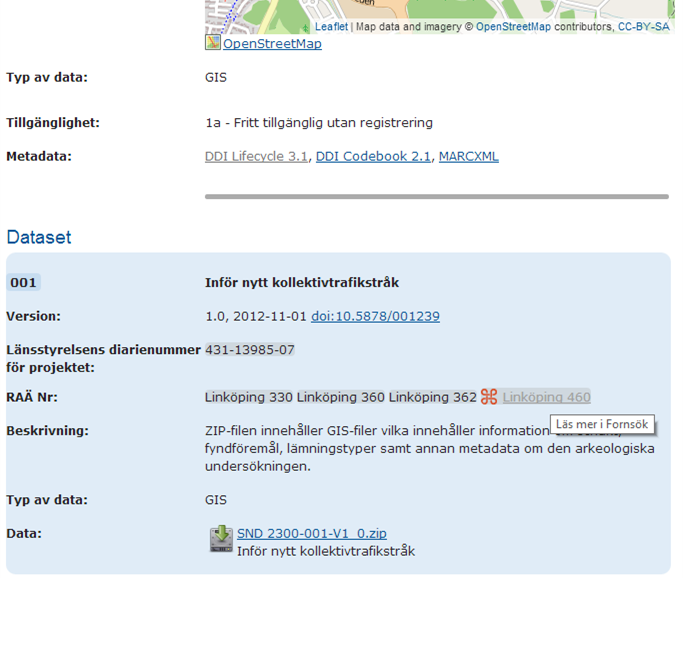
Olof och Stephanie jobbade på att koppla undersökningsdata lagrat hos SND (huvudsakligen från Ostlänkan projektet) till de berörda fornlämningarna hos FMIS. Detta ordnade de genom att använda sig av lämningarnas län och fornlämningsnumren, och att skicka anrop mot K-samsöks API. De hade i början problem med att även använda länsstyrelsernas diarienummren som ytterligare ett kopplingsfält, men dessa visade sig till sluts vara för knepiga.
De lyckades icke desto mindre hitta kopplingarna mellan undersökningsdatat och FMIS-posten med hjälp av K-samsök i de flesta fall (fornlämningsnummren kan också vara knepiga!) och tänker t.o.m. driftsätta denna tjänst i SNDs samlingar i snar framtid.
Rickard Larsson & Peter Östergren (RAÄ) – Kopplingar SND/K-samsök; Kopplingar K-samsök/Libris
Rickard och Peter hann med icke mindre än två insatser under hacket. För det första lyckades de göra samma sak som Olof och Stephanie, fast tvärtom – d.v.s. hitta kopplingar från fornlämningar i Kringla till ev. undersökningsdata hos SND. På det sättet ser man att länkarna blev ömsesidiga.
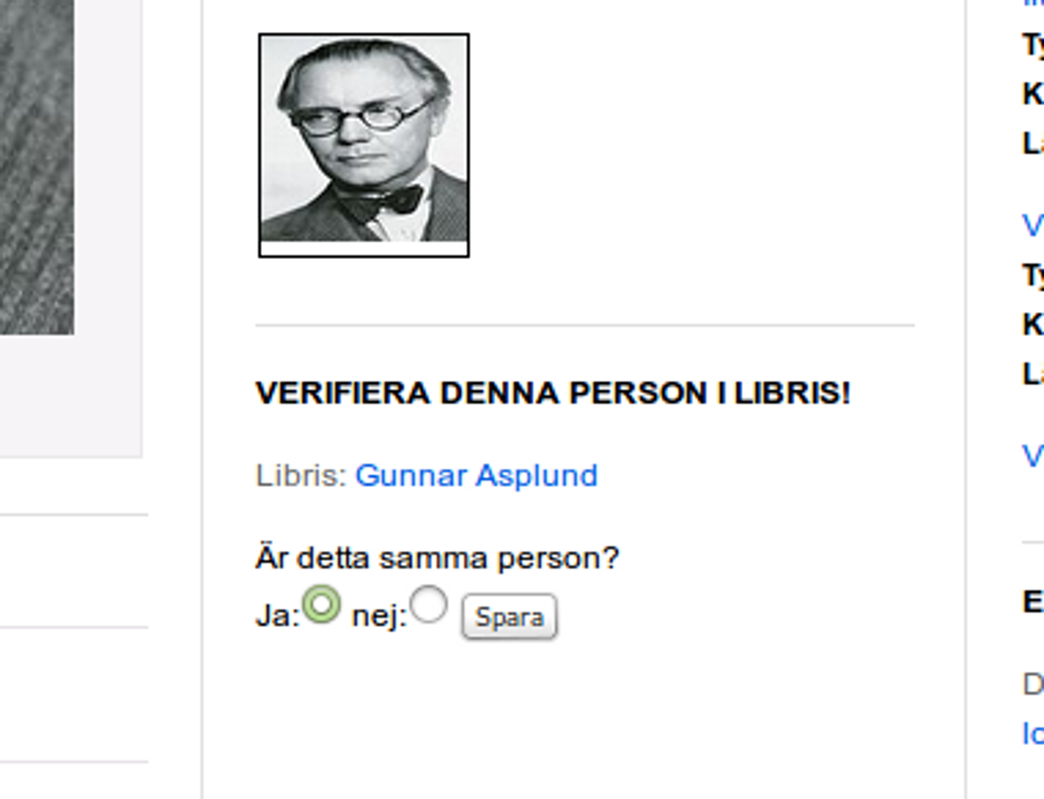
De lyckades även med ett skiss på ett ”crowdsourcing”-verktyg för Kringla, för att hitta, länka ihop, och kvalitetssäkra poster i K-samsök och Libris som beskriver samma person – t.ex. en arkitekt från Bebyggelseresitret eller en kung från Livrustkammaren mot en författare hos Libris. De hann bevisa en tekniskt ”proof-of-concept” tillsammans med skissar på hur gränssnittet skulle kunna se ut i praktiken, men själva tjänsten hann de inte skapa denna gång.
Erik Eriksson (SEAD) och Erik Lundborg (GisGruppen/Trafikverket) – Miljöarkeologisk data som GIS-lager

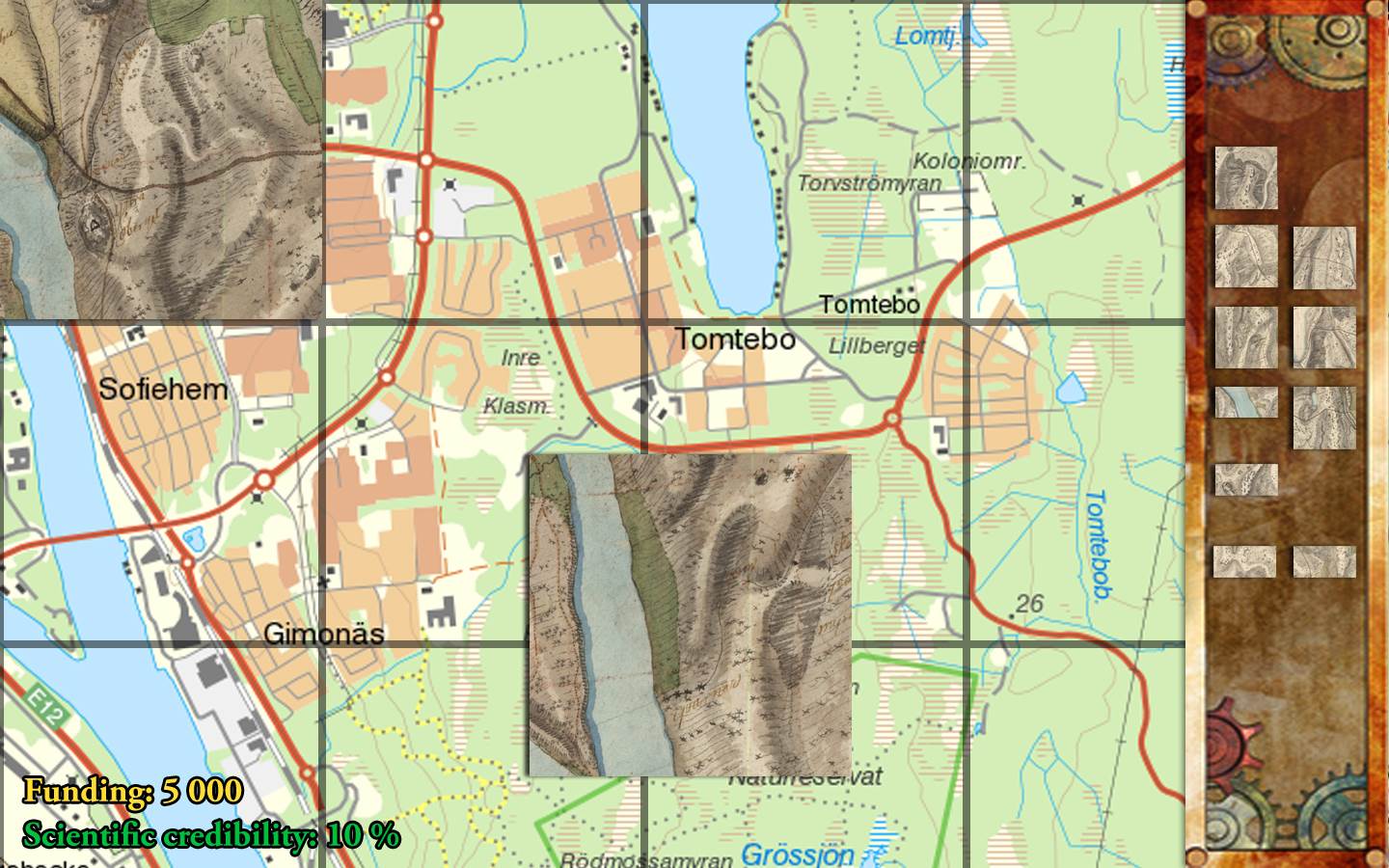
Erik E. jobbar på miljöarkeologidatabasen SEAD; Erik L. är GIS-människa. Tillsammans bestämde de sig för att extrahera data om miljöarkeologiska prov ur SEAD, och använda provens koordinater för att översätta SEADs innehåll till ett GIS-lager som skulle kunna användas som underlag för sammhällsplanering eller vägledsplanering av t.ex. Trafikverket.
Den här gruppen gjorde stora framsteg tidigt i hacket, men senare stötte på problem med koordinatdatat i SEAD: det visade sig att det inte bara var flera olika koordinatsystem i bruk (vilket inte var ett stort problem) utan även att koordinaterna var ofta omväxlade (x istället för y, och y istället för x). Trots detta lyckades de ändå visa ett fungerande och klickbar GIS-lager utifrån SEAD datat som med lite mer arbete skulle kunna användas till såväl planeringsunderlag som geofrafisk ingång till SEAD-datat för forskare.

Fredrik Palm, Sören Jonsson, & Roger Mähler (HUMlab) – Ortnamnsregister från befintliga källor
Fredrik, Roger, och Sören jobbade stenhårt på måndagen för att sy ihop ett ortnamnsregister från flera befintliga källor, för att det skulle kunna användas av Martin och Per i Kb-gruppen (ovan). Men såsmåningom visade det sig att det inte gick, och de valde istället byta spår och ägnade tisdagen åt att stödja Erik och Erik med sina koordinatproblem i SEAD-GIS arbetet.
Phil Buckland (SEAD), Ronny Smeds & Daniel Lind (Västerbottens museum), och Carl-Erik Engqvist (HUMlab) – Ett miljöarkeologiskt spel
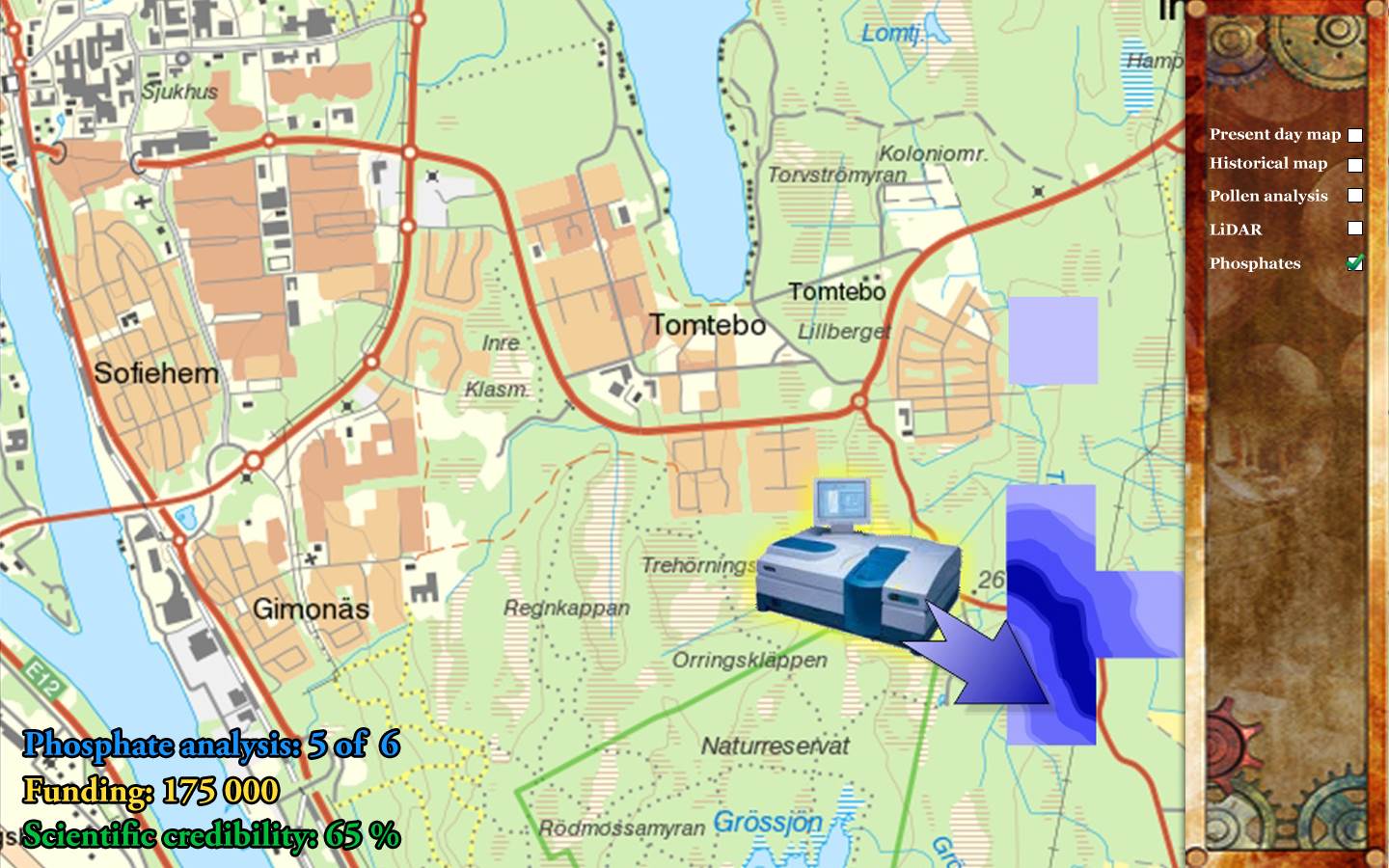
Phil, Ronny, Daniel och Calle jobbade på att få fram ett skiss på ett arkeologiskt dataspel. Spelet skulle byggas på SEADs miljöarkeologisk data, och skulle göra miljöarkeologi och arkeologi i stort intressant och spännande för de yngre. Idéen med spelet byggdes kring ett antal olika ”mini-spel” som skulle föreställa olika forsknings- och analysmetoder, t.ex. att matcha olika pollenarter (pollenanalys), eller flyga en helikopter över ett landskap för att skapa en höjdmodell (LiDAR), osv. Dessa mini-spel skulle i sin tur ingå i spelets övergripande narrativ där spelaren utforskar ett arkeologisk landskap med hjälp av olika metoder, och försöker samtidigt att öka sin vetenskaplig trovärdihet utan att alla sina forskningspengar ska ta slut.
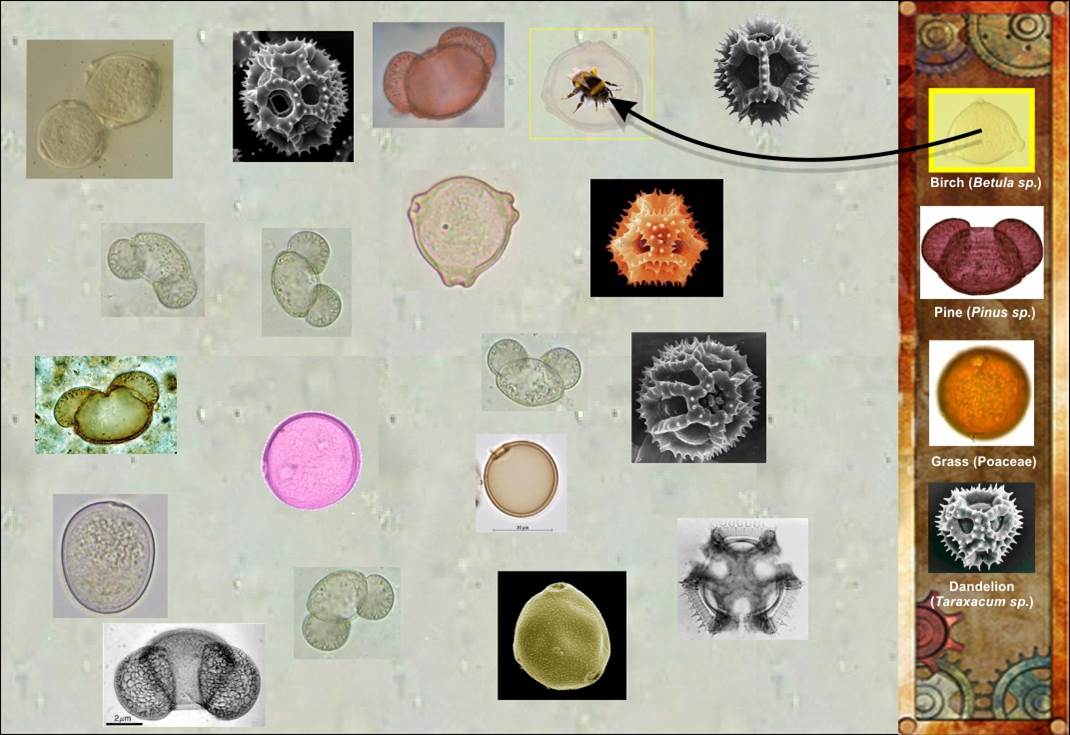
Skissen och idéerna kring hur spelet skulle fungera var lockande, väl genomtänkta och noggrant formulerade, men för att utveckla spelet på riktigt skulle det behövas investering av pengar och åtminstone ett par stycken heltidsutvecklare.
Sammanfattning
I sammanfattning var hacket väldigt lyckat. Samtliga deltagare gjorde värdefulla insatser inom ett antal områden, och vissa kom så långt inom tva dygn att de hade nästan färdiga lösningar som kan driftsättas. På presentationen av resultaten på seminariet på onsdagen mottogs gruppernas arbete positivt, och bra frågor ställdes av publiken.
Men den största framgången som kom ur hacket enligt min mening är att vi – deltagarna – som till vardags jobbar med olika system och datamängder inom olika verksamhetsområden lyckades jobba tillsammans och inom bara ett par dagar lära oss om varandras data och om nya tekniker och utvecklingsmetoder. Vi skapade nya relationer och förstärkte befintliga kopplingar, och förutsättningar för fortsatt samarbete och kunskapsutbyte även i andra sammanhang är starka. Det ser i alla fall jag fram emot!
3 kommentarer