I fredags avslutade Riksantikvarieämbetets program DAP ett kort internt hack om öppna länkade data på RAÄ. Hacket hölls över fyra dagar sprida över två veckor, och ordnades med hjälp av Martin Malmsten från Kungliga biblioteket, som har flera års erfarenhet av att jobba praktiskt med länkade data. Syftet med hacket var att bekanta våra IT-arkitekter och systemutvecklare med länkade data-teknik, och visa hur befintliga datamängder enkelt kan göras till länkade (och länkbara) data. Även att inleda en diskussion kring vägval för vår framtida länkade data, både vad gäller publicering och tjänster.

Bild: Åsa Sundin; CC-BY
JSON → JSON-LD
Vi tog som exempeldatamängd befintlig data som beskriver arkeologiska uppdrag. Uppdragsdatat togs fram som en del av vårt arbete med ett nytt uppdragsregister och registrering vid källan. Datat fanns som JSON, ett dataformat som är vanligt förekommande i webbtjänster, men som konstigt nog saknar stöd för länkar. Vi skapade en proof-of-concept arbetsflöde för att automatiskt mappa vår befintliga JSON till JSON-LD – en utökning av vanlig JSON med stöd för länkade data. Vi publicerade sedan detta på vår internwebb på ett sådant sätt att man kunde ställa frågor om datat. Det ursprungliga uppdragsdatat berikades ytterligare genom att länka det till data om lämningarna som hade berörts av uppdragen, tillhörande fynd, arkeologiföretagen som hade utfört uppdragen, och motsvarande beslut hos länsstyrelserna. Besluts- och företagsdatat skapades också utifrån det pågående arbetet kring uppdragsregistret, men länkade data om fynd och lämningar finns ju redan på K-samsök, och hämtades lätt därifrån.
Ändringarna som behövdes för att transformera det befintliga JSON-datat till JSON-LD var inte särskilt stora, men flödet som upprättades bestod icke desto mindre av flera steg för att få med alla beståndsdelar som behövdes för att beskriva datat. Till sluts hade vi tagit fram en automatiserad process som tog vanlig data och med några små ändringar lyckades översätta det till länkade data.
Modellering
För att vårt data ska vara interoperabel med andras måste det beskrivas på ett gemensamt och standardiserat sätt som andra förstår, eller åtminstone på ett sätt vars termer har väldefinierade översättningar till en sådan gemensam standard. I normalfallet skulle man ha en detaljerad domänmodell för internt bruk som skulle mappas till en mer generell men gemensam modell för publicering. Men för hackets kortsiktiga ändamål valde vi att helt enkelt använda en befintlig generell modell rakt av; i det här fallet, CIDOC-CRM och dess arkeologiska tillägg.
Med hjälp av CIDOC-CRM lyckades vi snabbt och enkelt beskriva relationerna mellan olika objekt – arkeologiska uppdrag, lämningar, rapporter, fynd, osv – på ett konsekvent och standardiserat sätt. Nyanserna man vanligtvis skulle önska sig förloras om man bara kör rå CIDOC-CRM utan att bygga något mer verksamhetsnära ovanpå det, men det är däremot en bra modell för informationsutbyte om man vill kunna kombinera kulturarvsdata från flera olika källor (sannolikt med varsin specifik datamodell) vilket är hela poängen med länkade data.

Bild: Marcus Smith, CC-BY
För hacket hade vi inte så många olika sorters objekt att modellera: lämningar, arkeologiska uppdrag, rapporter, fynd, arkeologiföretag, och länsstyrelser. Vi försökte förhålla oss till DAP-programmets övergripande informationsmodell, som passar väldigt bra med CIDOC-CRM.
Tripletter och SPARQL
Sista steget efter att mängden data var översatt till länkade RDF data i form av JSON-LD var att mata in det i en triplestore. RDF-data består i grund och botten av påståenden med tre delar: subjekt, predikat, objekt; dessa tre delar kallas för en tripplett. En triplestore är en sorts databassystem som hanterar data i form av sådana tripletter, istället för de vanliga tabellerna med rader och kolumner. De flesta triplestores har även stöd för det länkade data frågespråket SPARQL. Det var först här att både deltagarna och åskådarna började uppleva nyttan med länkade data under hacket.
Vi hade egentligen två separata triplestoredatabaser igång på olika datorer: en databas med information om arkeologiska uppdrag, länsstyrelsebeslut, och arkeologiföretag; och en databas med information från K-samsök om lämningar mm. Eftersom det var länkade data vi jobbade med kunde vi plötsligt ställa komplicerade frågor som använde data från båda databaserna. T.ex. “Visa mig alla arkeologiföretag som har upphandlats av länsstyrelse X de senaste fem åren,“ eller, “Visa vilka sorters uppdrag arkeologiföretag A har utfört i B län, och vilka lämningstyper de undersökte.“
Men vi var ju inte begränsade till bara vår data: informationen från K-samsök innehöll även länkar till litteraturposter i Kungliga bibliotekets länkade datatjänst Libris om verk som handlade om lämningarna. Plötsligt kunde vi ställa federerade frågor som hämtade data från sådana externa tjänster och kombinerade det med vår egen data:
“För ett uppdrag, visa dess uppdragstyp, namnet på utförande organisationen, ärendenummret hos länsstyrelsen, vilka lämningstyper undersöktes, och titel + författare för samtliga böcker/artiklar som har skrivits om lämningarna:“
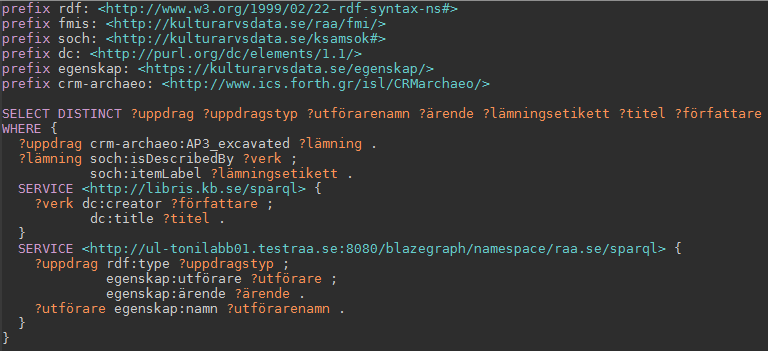
Bild: Marcus Smith, CC-BY
Libris är ju långt ifrån den enda SPARQL-servern med länkade data som är av intresse för oss; om vi hade haft mer tid hade vi även kunnat ställa likadana frågor tvärs ett antal heterogena datamängder med länkade data och SPARQL-gränssnitt. Vi skulle ha kunnat hitta beskrivningar på de aktuella lämningarna och lämningstyperna från DBpedia eller Wikidatas SPARQL-server, eller hitta lämningar av samma typ eller med likadana fynd i Archaeology Data Service’s länkade data tjänster. Men tiden var uppe för hacket, och vi hann inte längre.
Länkade data gör att alla de här resurserna går att jämföra och koppla ihop, men SPARQL gör att de går att kombinera på det här enkla sättet. Tänk om alla hade skapat en egen API för varje tjänst och datamängd; då hade man behövt lära sig RAÄs API, Libris API, ADS API, Wikidatas API, och sedan skriva kod för att ställa frågor till dem på varsitt sätt och kombinera resultaten. Men eftersom alla tillämpar SPARQL, en gemensam API för all länkade data, så slipper vi sådant strul och dubbelarbete.
Resultat och fortsättning
Hacket lyckades med sitt mål att bevisa hur enkelt det är att mappa vårt befintligt data till länkade data, och nyttan som kan uppstå. Våra arkitekter och utvecklare blev även mer bekanta med länkade data-teknik genom att få en praktisk övning. Vi lyckades dessutom visa nyttan med tekniken, att beskriva vårt data på ett standardiserat länkbart sätt, och att visa på möjligheterna det skapar både inom vår egen verksamhet men även för återanvändning av andra.
Vi kommer att fortsätta jobba med länkade data inom DAP framöver, och det blir säkert fler labbar och hack i samma stil som den här. Nästa steget för oss är, att börja uttrycka DAP-programmets informationsmodell som RDF, med kopplingar till mer generella standarder som CIDOC-CRM, MIDAS, osv; och att upprätta auktoritetsposter för svenska kulturarvsbegrepp – t.ex. lämningstyper, uppdragstyper, kronologiska perioder – som kan användas som referensdata i länkade data-världen.
Vi är väldigt tacksamma till Martin Malmsten och Kungliga biblioteket för hjälpen med hacket, och ser mycket fram emot fortsatt samarbete.
Program, data, och exemplar som skapades under hacket finns tillgängliga på GitHub.