
Kan fastighetsbeteckning fungera som en länk mellan Bebyggelseregistret och Statens konstråds arkiv över offentlig konst? Anders Nygårds, praktikant och student vid Uppsala universitet, har under några veckor undersökt hur länkade öppna data kan användas för knyta samman två myndigheters databaser med konst och kulturarv. Här berättar han om arbetet.
Vårterminen 2020 gick jag en D-kurs konstvetenskap med titeln “Offentlig konst som framtidens kulturarv” vid Uppsala universitet. Trots att pandemin bröt ut hann vi genomföra studiebesök och föreläsningar innan distansundervisning kom att dominera. Under kursen fick vi besöka både Riksantikvarieämbetet och Statens konstråd och vi fick höra talas om satsningarna på att stärka kunskapsöverföringen mellan de två myndigheterna. Den nya rapporten Byggnadsanknuten offentlig konst – Kunskapshöjande insatser för förvaltning av den offentliga konsten som del av kulturmiljön hade just släppts och till kurslitteraturen hörde den bredryggade fallstudien Offentlig konst Ett kulturarv, ett FoU projekt från Riksantikvarieämbetet utfört av Statens konstråd.
För mig var de här texterna inspirerande då de pekade ut ökade satsningar på digitalisering som ett viktigt område för framtiden, exempelvis att via öppna länkade data och med relativt små insatser kunna gifta samman information mellan olika myndigheter. Att användare av Bebyggelseregistret skulle kunna se att den gråa betongbyggnaden Garnisonen på Karlavägen har ett flertal konstverk presenterade i Konstrådets arkiv över offentlig konst.
Genom länkade öppna data kan dessa uppgifter bli tillgängliga på webbsidorna utan att någon ytterligare registrering behövdes. Det gick att läsa i den förstnämnda rapporten att arbetet med att tillgängliggöra dessa öppna data inleddes redan 2015, i dialog med Digisam. Det är värdefullt inte bara för allmänheten, utan framförallt för att se till att konstnärliga värden inte går förlorade vid ombyggnad och restaurering.
Att länka samman dataregister
När jag vid kursens slut gick in och letade i Bebyggelseregistret insåg jag att själva integrationen ännu inte genomförts, och det fick mig att ta kontakt med berörda myndigheter. Detta ledde så småningom till den fantastiska möjligheten att få praktisera på både Riksantikvarieämbetet och Statens konstråd i syfte att lära mig mer om just länkade öppna data i konst- och kulturarvssektorn. Praktiken utgjorde en del i det konstvetenskapliga masterprogrammet vid Uppsala universitet, där jag gör ett examensarbete om tillgängliggörande av den offentliga konsten via digitalisering. Att i någon liten mån få vara delaktig i det arbetet på Riksantikvarieämbetet har verkligen varit spännande.
Så vad är det då jag tillsammans med min handledare Marcus Smith har gjort under dessa fem veckor? Målsättningen var att undersöka möjligheten att göra verklighet av den från flera håll uppkomna idén att knyta ihop den tillgängliggjorda informationen om offentlig konst med kulturarvs-aggregatorn K-samsök eller möjligen bara Bebyggelseregistret. Vi inledde perioden med ett möte med Statens konstråd, och senare även med teamet bakom Bebyggelseregistret på Riksantikvarieämbetet. Samtalen ledde fram till beslutet att använda UGC-hubben i K-samsök som teknisk lösning för att specifikt knyta ihop databaserna.
Med hjälp av UGC-hubben så kan länkar mellan byggnader och relaterad konst publiceras utan att man behöver ändra i vare sig Bebyggelseregistret eller Statens konstråds register. När länkarna publiceras i UGC-hubben kan resultatet sedan visas i söktjänsten Kringla, eller vilket annat sökverktyg som helst som kan använda sig av länkad data. K-samsök har därmed den information som behövs för att knyta samman fastigheter i Bebyggelseregistret med den byggnadsanknutna offentliga konsten.
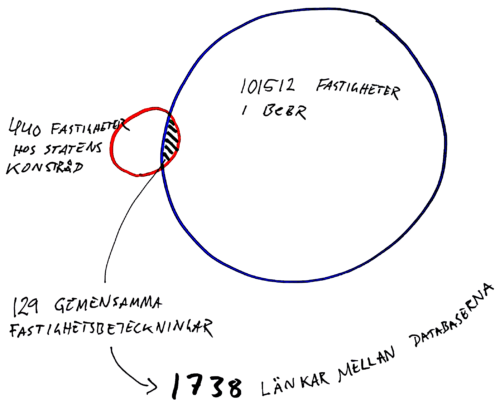
Modellen med en oberoende utvecklingsmiljö tog bort behovet av att involvera mig som tillfällig praktikant i en skarp utvecklingsmiljö med allt vad det innebär. Istället utfördes arbetet i en lokal utvecklingsmiljö, vilket i sig är ett bevis på flexibiliteten med länkade öppna data. Ganska snart gick det att ställa frågor till datan som gav svar på hur det i praktiken fungerade att använda fastighetsbeteckning som sammanlänkande nyckel.
Den mänskliga faktorn
Det visade sig att en hel del fastighetsbeteckningar var felaktigt inmatade – ett faktum som förvånade mig mer än Marcus – men trots detta fick vi en ganska god överlappning där länkar mellan Statens konstråds konst och Bebyggelseregistrets objekt kunde definieras. Och när man nu känner till de här bristerna i inmatade fastighetsbeteckningar är det för övrigt ingen stor sak att korrigera dessa och på så vis öka antalet länkar betydligt.
Läget nu när jag fått chansen att sammanfatta försöken är alltså att en snitslad bana till att skapa en import av länkar till UGC-hubben är klar. Det återstår arbete med att presentera dessa länkar i den idag möjliga målmiljön Kringla. Men den naturliga platsen för länkar till den offentliga konsten är såklart Bebyggelseregistret – som det också uttrycks i rapporten Byggnadsanknuten offentlig konst.
Jag hoppas därför att resultatet från min praktik kan få fungera som inspiration eller utgångspunkt till en tillämpning av länkade öppna data mellan Statens konstråd och Riksantikvarieämbetet.
– Anders Nygårds (LinkedIn)
Se även den 2022 utkomna rapporten Byggnadsanknuten offentlig konst: metod för värdering utifrån kulturhistoriska och estetiska aspekter.