I det fenomenala webbklippet där Guy Kawasaki berättar om 12 saker han lärde sig av Steve Jobs är ett av huvudnumren “jump to the next curve“. Under diskussioner kring hur vi ska utveckla K-samsök i framtiden försökte vi på utvecklingsenheten på Riksantikvarieämbetet bryta ner vad detta kan tänkas innebära. Denna blogpost är en utveckling av den diskussionen. Resonemanget som förs av Jobs/Kawasaki handlar om att man inte ska jobba på att fördjupa en verksamhet inom det område som den just nu är mest välmående, utan att man ska hoppa till nästa utvecklingskurva och börja jobba där – det är så man når framgång i framtiden. Man kan också kalla det att jobba långsiktigt. Ett av Kawasakis exempel är isutbärarna. I en värld där det inte finns kylskåp, men isskåp, finns det en stor marknad för isutbärare, dvs folk som jobbar med att flytta iskuber mellan islager och isskåp i folks hem. När kylskåpen kom upphörde inom kanska kort tid isutbärarna att existera som yrkeskår. Den som uppfann kylskåpet hade hoppat till “nästa kurva“, och de som jobbade med att anställa fler isutbärare hade hållit sig till det gamla paradigmet.
Den intressanta frågan som vi diskuterat är hur detta kan appliceras på en tjänst som K-samsök? Här har vi en tjänst som aggregerar information från flera olika institutioner (i skrivande stund 60 st) i en enda sökbar tjänst. Vi labbade lite med begreppen och konstaterade att själva aggregeringen förmodligen är en egen “kurva“ inom utvecklingen av hur man hanterar sammanställning av information. Jag gjorde en skiss över det hela för att illustrera:
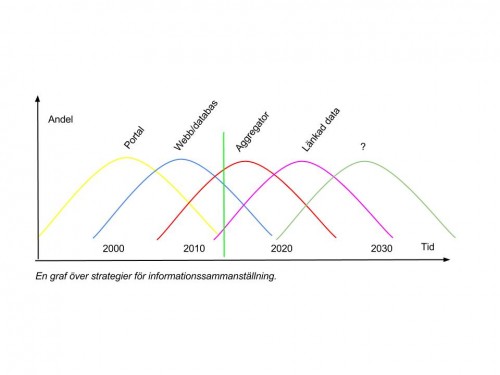
Här följer en kort presentation av vad som avses med de olika kurvorna.
1. Gul kurva:Â Portaler. När webben var relativt ny ville man försöka samla länkar till olika områden som man tyckte var intressant i så kallade “portaler“. Många stora företag byggde portaler för snabb åtkomst åt sin data, och även på Riksantikvarieämbetet fanns det ett portalprojekt (kallat “Kulturmiljöportalen“). Under denna kurvas dominans handlar webb i väldigt hög utsträckning om att koda HTML, och många som hade gått en kortkurs i textuppmärkning blev “it-gurus“, ganska oförtjänt. Men sökmotorer som Google blev snabbt effektivare än portalerna, och när de sociala webbarna började dominera blev det ofta enklare för användaren att skriva frågan man hade på ett forum, eller att söka på nätet för att hitta sin information. Då hade dock redan kurva 2, som jag här kallar webb/databas börjat dominera.
2. Blå kurva: Webb/databas. Här hanteras inte längre information som enskilda sidor på servrarna, utan lagras i databaser vilket t ex möjliggör för den sociala webben – nu kan folk kommentera eller logga in på sajter. Detta i sin tur försvårar för sökmotorerna som måste börja indexera innehåll på nya sätt. Nu är det också möjligt att hålla sin data i sökbar form på webben i ett webbgränssnitt, men det är svårt att koppla flera söktjänster till varandra. Snart uppfinner man APIer som löser detta problem (och gör att man kan komma åt data i en tjänst från flera olika databaser samtidigt). Här börjar separationen mellan data och tjänst att bli tydlig – tidigare har ju kopplingen mellan presentationsformatet och innehållet varit hundraprocentlig (precis som på den analoga tiden).
3. Röd kurva:Â Aggregering. Men det finns ändå problem med att data lagras i enskilda databaser, i så kallade “informationssilos“. Även om data från olika håll kan användas i en och samma tjänst är det svårt att veta vilka datamängder som hänger ihop, och på vilka sätt. Därför uppfinner man aggregaten, nya databaser som oftast sammanställer metadata från flera olika håll och gör denna metadata sökbar via ett gränssnitt. Här ensar man också metadatat så att man kan få någorlunda bra överenesstämmelse mellan de olika datamängderna i sin sökning (vilket är en mer än omfattande process eftersom de ofta har olika ursprung och olika metoder för att lagra in datat). Aggregaten fyller också rollen att exponera datamängder som ännu inte har något gränssnitt mot webben.
4. Lila kurva: Länkade öppna data. Men det går ju inte att aggregera allt, det finns nämligen inget slut på hur mycket man kan behöva aggregera (snart sitter man i en situation där man har aggregerat mer eller mindre hela webben). Anledningen till detta är att digital information till skillnad från analog är i sitt absoluta esse när den kopplas till andra datamängder. Konsekvensen av detta blir i sin tur att data bara lagras där det skapas, för att sedan användas på massa andra ställen. Denna modell kallas “Länkade öppna data“, och utgår från metoder för informationssammanställning som Tim Berners-Lee hittade på och kallade för den semantiska webben, eller webb 3.0. Istället för att bara ställa frågor till datat på ett ställe så skickar man frågan till mängder av ställen baserat på länkar.
5. Grön kurva:Â ?. Det är så långt vi tror oss ha en uppfattning just nu. Vad som händer efter en semantisk webb kan vi bara spekulera i, men det ingår inte i scopet för den här blogposten.
Man kan dra lite slutsatser av kurvorna och hur de framträder. Till att börja med är det dock bra att säga att detta är en skiss och en tolkning av en verklighet som förstås är mycket mer komplex än så här. Alla bilder av verkligheten är per definition förenklingar. Men de kan hjälpa oss att sortera i begreppen. En tydlig trend är att vi rör oss från att data är “sökbar“ till att den är möjlig att ställa frågor till – blir bearbetningsbar eller “queryable“. Nu handlar det inte bara om att hitta fram till ett objekt, utan att kunna hitta ett urval baserat på en (kanske ganska komplex) urvalsfråga. Det spekuleras i om inte detta kommer att leda fram till nya yrkeskårer inom branscherna, någon form av digitala kuratorer eller bibliotekarier.
En annan tydlig sak är att vi rör oss på flera kurvor samtidigt. Det gröna strecket representerar nu, 2013, och man kan kanske konstatera att det (nästan) inte är någon som talar om portaler längre. Det är lite Länkade öppna data på uppseglande men många jobbar fortfarande med stängda databaser kopplade till ett sökgränssnitt. Aggregaten är ganska många.
Som vi har resonerat måste K-samsök ta fasta på det som gör aggregatet unikt i en värld där Länkade öppna data är normen. Annars kommer det inte längre att vara värdefullt för informationsförvaltarna att delta med sin information i den form av jätteindex som K-samsök utgör. Det kommer fortfarande under ganska lång tid att vara en väg ut för institutioner som inte har förmåga eller kunskap kring att lägga ut sin data som RDF-filer på egen hand (då kan ju K-samsök lösa det åt dem), men för den ökande mängd institutioner som gärna vill nå ut med sin data direkt måste det finnas mervärden.
Återstår gör att identifiera dessa.
>> Henrik Summanen jobbar med K-samsök och Länkade öppna data på Riksantikvarieämbetet.